AI / ML · 2024
LLM Distillation for Financial Reports
Using knowledge distillation to build a financial-analysis model that is computationally efficient and specialized for financial contexts — without the cost of hosting a full-size LLM.
Problem
We used distillation to develop a financial-analysis tool that is computationally efficient and simpler than traditional LLMs, while being specialized for financial contexts. LLMs cannot be efficiently used and hosted on an ad-hoc basis — so we aimed to train smaller models that are easily accessible.
Why It Matters
Financial-analysis tools are essential for evaluating a company's fiscal health. Current tools demand significant computational resources while remaining too general to stay consistently accurate in financial contexts. Distillation combines the strengths of multiple models while being far more resource-efficient — making advanced financial analysis accessible, and improving decision-making across industries.
Methodology
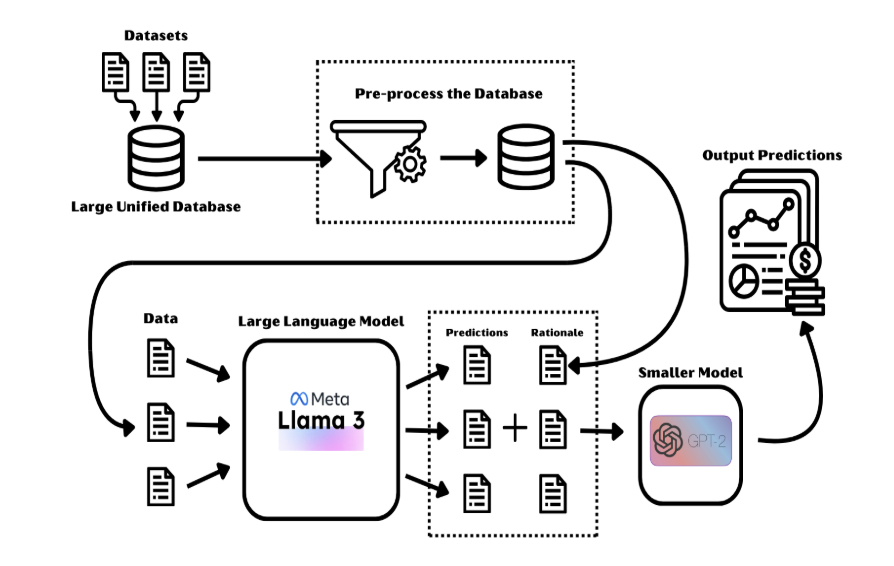
The approach is depicted in Fig. 1. We take a large unified dataset, perform the required preprocessing, and pass it to large, renowned LLMs such as Claude 3.5 Haiku and Meta's Llama 3 to generate “labels” and “rationales.” Combining these, we train a much smaller model (in terms of parameters — e.g. Flan-T5 or GPT-2) on the outputs and rationales of the big models.
Discussion
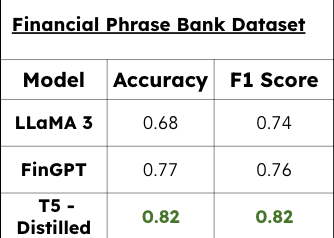
LLaMA 3 and Claude 3.5 excel in similar areas, making distillation effective for combining their strengths. T5 distilled from LLaMA 3 outperforms FinGPT — indicating that step-by-step distillation is more effective than fine-tuning or LoRAs, offering cost-efficient performance and suggesting distillation is a promising optimization strategy.
Results
We provided a model that outperforms current LoRAs and fine-tuned GPTs using less than 12% of the original dataset (Sentiment Train FinGPT) on the FPB benchmark. It not only takes less training time, but inference is dramatically faster — making the model usable in resource-constrained systems.